Posted on: October 30, 2019 03:18 PM
Posted by: Renato
Categories: Variados linux postgresql database sql
Views: 1387

O Vacuum é um utilitário que deve ser usado pelo DBA como manutenção diária do Banco de Dados. Não creio que exista um banco com um utilitário como esse, o qual precisa ser utilizado praticamente diariamente. No entanto, o vacuum existe devido ao controle exclusivo de transação que o postgreSQL possui: o MVCC. As duas principais operações realizadas por essa ferramenta são:
- Recuperar espaço em disco devido a registros atualizados ou deletados;
- Atualizar as estatísticas utilizadas pelo otimizador para determinar o modo mais eficiente de executar uma conusulta no PostgreSQL.
Quando realizamos um UPDATE o registro propriamente dito não é alterado; é incluído um novo registro clone. Sendo assim, o PostgreSQL marca o registro "original" (antigo) como expirado e realiza a alteração no clone. Se for um DELETE, o PostgreSQL apenas marca o registro deletado como expirado. Por isso, é normal vermos a base de dados crescer de forma descomunal no PostgreSQL e as pesquisas começarem a ficar cada vez mais lentas. Esta lentidão fica mais visível principalmente se a consulta não for indexada e for utilizado acesso seqüencial, que faz com que o PostgreSQL verifique TODOS os registros (incluindo os expirados) para localizar o dado. No caso do Índice, ele é o responsável por localizar o dado.
Quando executamos o Vacuum, o mesmo remove fisicamente o dado expirado, pega os dois últimos registros da tabela e joga no lugar do “buraco”.
No segundo caso, o PostgreSQL analisa a quantidade de registros, relacionamentos e índices para atualizar uma feature do PostgreSQL chamada “query planner”. Esta funcionalidade analisa as tabelas gerando informações úteis ao PostgreSQL a fim de que as queries consigam ser aproveitadas de uma maneira mais eficiente em tempo de execução.
vacuum VERBOSE ANALYSE
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ tabela ]
VACUUM [ FULL ] [ FREEZE ]
[ VERBOSE ] ANALYZE [ tabela [ (coluna [, ...] )] ]
| FULL | Seleciona uma limpeza "completa", que pode recuperar mais espaço, mas é muito mais demorada e bloqueia a tabela em modo exclusivo. |
| FREEZE | Seleciona um "congelamento" agressivo das tuplas. |
| VERBOSE | Produz um relatório detalhado da atividade de limpeza de cada tabela. |
| ANALYZE | Atualiza as estatísticas utilizadas pelo otimizador para determinar o modo mais eficiente de executar uma consulta. |
| tabela | O nome da tabela específica a ser limpa. O padrão é que sejam todas as tabelas do banco de dados corrente. |
| coluna | O nome da coluna específica a ser analisada. O padrão é que sejam todas as colunas. |
:sql_magazine=> VACUUM VERBOSE ANALYZE tabela_teste;
Poderiamos executar no Prompt de Comando do Sistema Operacional, através de um script chamado vacuumdb:
#vacuumdb –a –f –z –v
Executando o vacuum em TODOS OS BANCOS existentes no PostgreSQL.
| -a | Todos os Banco de Dados. |
| -f | Full |
| -z | Analyze |
| -v | Exibe mensagens de debug |
Se fôssemos fazer exatamente como no commando VACUUM VERBOSE ANALYSE tabela_teste, seria:
#vacuumdb –t tabela_teste banco_teste –v –z BANCO
É muito importante usar diariamente o Vacuum, por isso, não se esqueça deste utilitário pois ele nos poupa dor de cabeça. Uma boa forma é usar o gerenciador de tarefas agendadas do sistema Operacional (no caso do Linux, o cron). Eu sempre executo um Vacuum às 23:00h. (antes do meu backup) e às 4:00 h. (antes dos operadores iniciarem o trabalho).
Um dado importante: O Vaccum FULL usa acesso exclusive da Tabela, ou seja, poderá travar a tabela (lock), se necessitar ser executado com operadores conectados. Execute o vacuum sem o parâmetro FULL.
Description
VACUUM reclaims storage occupied by dead tuples. In normal PostgreSQL operation, tuples that are deleted or obsoleted by an update are not physically removed from their table; they remain present until a VACUUM is done. Therefore it's necessary to do VACUUM periodically, especially on frequently-updated tables.
Without a table_and_columns list, VACUUM processes every table and materialized view in the current database that the current user has permission to vacuum. With a list, VACUUM processes only those table(s).
VACUUM ANALYZE performs a VACUUM and then an ANALYZE for each selected table. This is a handy combination form for routine maintenance scripts. See ANALYZE for more details about its processing.
Plain VACUUM (without FULL) simply reclaims space and makes it available for re-use. This form of the command can operate in parallel with normal reading and writing of the table, as an exclusive lock is not obtained. However, extra space is not returned to the operating system (in most cases); it's just kept available for re-use within the same table. VACUUM FULL rewrites the entire contents of the table into a new disk file with no extra space, allowing unused space to be returned to the operating system. This form is much slower and requires an exclusive lock on each table while it is being processed.
When the option list is surrounded by parentheses, the options can be written in any order. Without parentheses, options must be specified in exactly the order shown above. The parenthesized syntax was added in PostgreSQL 9.0; the unparenthesized syntax is deprecated.
test=# \h VACUUM
Command: VACUUM
Description: garbage-collect and optionally analyze a databaseSyntax:
VACUUM [ ( { FULL | FREEZE | VERBOSE | ANALYZE } [, …] ) ]
[ table_name [ (column_name [, …] ) ] ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table_name ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ]
ANALYZE [ table_name [ (column_name [, …] ) ] ]
Configurando VACUUM e autovacuum
Nos primeiros dias dos projetos do PostgreSQL, as pessoas tinham que executar o VACUUM manualmente. Felizmente, isso se foi há muito tempo.
Atualmente, os administradores podem contar com uma ferramenta chamada autovacuum , que faz parte da infraestrutura do PostgreSQL Server.
Ele cuida automaticamente da limpeza e trabalha em segundo plano. Ele é ativado uma vez por minuto (pode ser modificado ajustando autovacuum_naptime = 1 no postgresql.conf) e verifica se há trabalho a ser feito.
Se houver trabalho, o autovacuum dividirá até três processos de trabalho (pode ser modificado por autovacuum_max_workers no postgresql.conf).
A principal questão é quando o vácuo automático aciona a criação de um processo de trabalho? A resposta para esta pergunta pode ser encontrada novamente em postgresql.conf:
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
autovacuum_analyze_scale_factor = 0.1
O comando autovacuum_vacuum_scale_factor informa ao PostgreSQL que vale a pena aspirar uma tabela se 20% dos dados foram alterados. O problema é que, se uma tabela consiste em uma linha, uma alteração já é 100%. Não faz absolutamente sentido fazer um processo completo para limpar apenas uma linha. Portanto, autovacuum_vacuuum_threshold diz que precisamos de 20% e esses 20% devem ter pelo menos 50 linhas. Caso contrário, o VACUUM não entrará em ação.
O mesmo mecanismo é usado quando se trata de criação de estatísticas do otimizador. Precisamos de 10% e pelo menos 50 linhas para justificar novas estatísticas do otimizador. Idealmente, o autovacuum cria novas estatísticas durante um VACUUM normal para evitar viagens desnecessárias à tabela.
Se você achou este artigo interessante, pode explorar o Mastering PostgreSQL 11 para dominar os recursos do PostgreSQL 11 para gerenciar e manter eficientemente seu banco de dados. O domínio do PostgreSQL 11 pode ajudá-lo a criar soluções dinâmicas de banco de dados para aplicativos corporativos usando a última versão do PostgreSQL, que permite aos analistas de banco de dados projetar os aspectos físicos e técnicos da arquitetura do sistema com facilidade.
Fonte: https://medium.com/coding-blocks/optimizing-storage-and-managing-cleanup-in-postgresql-c2fe56d4cf5
É muito importante, principalmente para um >DBA, conhecer e analisar as ferramentas que possam aumentar a performance do banco de dados, isso porque geralmente empresas que possuem >DBA trabalham com uma grande quantidade de dados e a velocidade de resposta da aplicação torna-se crítica para seu negócio. Imagine, por exemplo, uma Operadora de Cartão de Crédito, como Visa ou Mastercard: quantos milhões de transações por segundo são realizadas em todo mundo? É fato que um index errado em um banco de dados dessa operadora pode ser fatal para perda de milhões de reais em poucos segundos.
VACUUM
Antes de entender como funciona tal técnica é importante conhecer o funcionamento interno do PostgreSQL para assim ver a real utilidade da mesma.
Você já percebeu que ao deletar registros do seu banco de dados ele não diminui ? Faça o teste: compare o tamanho atual do seu banco de dados com o tamanho após a deleção de muitos registros, você ficará surpreso ao perceber que nada mudou. Então você deve se perguntar: Mas se eu estou deletando, o mais lógico é diminuir o tamanho do banco, certo? Negativo. O PostgreSQL, assim como outros bancos, na verdade não deletam os registros e sim os marca como inúteis, técnica muito comum e utilizada em diversas aplicações, ou seja, se você fizer um “>DELETE FROM funcionario WHERE id > 100” e este comando deletar 10 mil linhas, você na verdade estará marcando as 10 mil linhas como inúteis e não deletando fisicamente, o que demandaria muito mais tempo e recurso.
A lógica é a seguinte:é muito melhor ter uma operação rápida do que espaço em disco, sendo assim o banco ficará enorme mais sua performance compensará tal perda de espaço, que hoje em dia acaba não trazendo muito impacto, já que 'armazenamento digital' está barato e acessível.
Todo esse mecanismo é chamado de MVCC (Multiversion Concurrency Control) que garante uma performance melhor ao banco de dados, afinal performance é o ponto chave em aplicações críticas. Quando você realiza um >UPDATE, o seu registro é atualizado, correto? Negativo. O que na verdade é feito é uma inserção de outra tupla na sua tabela, com os mesmos dados da tupla original, apenas alterando o que você solicitou no >UPDATE, e a tupla anterior (não atualizada) é marcada como inútil, assim como explicamos no >DELETE.
Dado todas as explicações acima, chegamos ao ponto chave do artigo: a utilização do >VACUUM. Já que temos muitos registros que estão marcados como inúteis, precisamos em algum momento limpar estes, para garantir ainda mais performance em nosso banco e retirar toda sujeira de dados.
No momento em que o comando >VACUUM é executado, é feita uma varredura em todo o banco a procura de registros inúteis, onde estes são fisicamente removidos, agora sim diminuindo o tamanho físico do banco. Mas além de apenas remover os registros, o comando >VACUUM encarrega-se de organizar os registros que não foram deletados, garantindo que não fiquem espaços/lacunas em branco após a remoção dos registros inúteis.

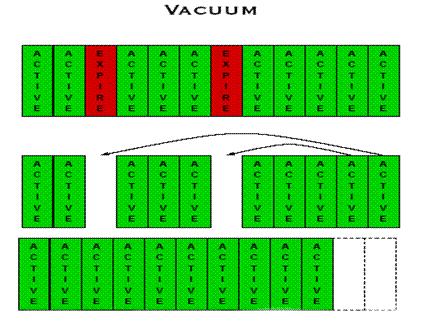
Na Figura 1 você pode notar um exemplo simples e prático de como funciona o >Vacuum:
- Temos na Listagem 1 a lista de todos os registros, incluindo os úteis e inúteis (marcados em vermelho).
- O >vacuum deleta todos os registros inúteis (em vermelho), mas após essas deleções serem realizadas, você pode perceber que ficam espaços em branco, exatamente o espaço onde estavam os registros inúteis.
- Por fim, o >vacuum encarrega-se de remover esses espaços, garantindo que os mesmos fiquem organizados e em uma disposição correta.
Há ainda um quarto e último passo realizado pelo >vacuum, que não está descrito na figura acima. Ocorre que o >vacuum também atualiza as estatísticas que são utilizadas pelo otimizador do PostgreSQL para determinar qual a melhor forma de realizar uma busca no banco de dados, porém, a atualização dessas estatísticas vai depender da forma em que o >vacuum for executado, o que explicaremos mais a frente do porque.123VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ tabela ]VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ tabela [ (coluna [, ...] ) ]]Listagem 1. Sintaxe do Vacuum
Acima você pode ver toda a parametrização do comando vacuum, com suas possíveis opções, então vamos explicar cada uma delas e sua utilidade:
- >#FULL : Quando o vacuum é utilizado em conjunto com este parâmetro, então é feita uma limpeza completa de todo o banco, em todas as tabelas e colunas. Este processo geralmente é demorado e evita que qualquer outra operação no banco seja realizada, ou seja, ao realizar um >VACUUM FULL você terá que esperar todo processo terminar até realizar um comando >DLL ou >DML.
- >#VERBOSE: Ao ativar esse parâmetro você terá um relatório detalhado de tudo que está sendo feito no comando >VACUUM.
- >#ANALYSE: Você lembra que citamos anteriormente que o >VACUUM em um último passo pode ou não atualizar as estatística que são utilizadas pelo otimizador do PostgreSQL para determinar o melhor método de consulta? Este parâmetro é responsável por habilitar ou desabilitar este tipo de atualização, em outras palavras, ao usar o >ANALYSE junto ao seu comando >VACUUM ele irá atualizar as estatística do banco de dados a fim de melhorar a performance das pesquisas.
- >#tabela: Caso você queira realizar o >VACUUM apenas em uma tabela, então você deve especificar explicitamente qual tabela será, caso contrário, apenas deixe este parâmetro em branco e todas as tabelas serão consideradas.
- >#coluna: Seguindo o mesmo raciocínio da tabela, caso você deseje realizar o >VACUUM em apenas algumas colunas, basta especificar quais são, caso contrário, deixe este parâmetro em branco e todas as colunas serão consideradas.
Algo que você pode ser perguntar é qual a diferença entre o >VACUUM sem parâmetros (simples) e o >VACUUM FULL (que exige o bloqueio exclusivo das tabelas, ou seja, nenhuma operação pode ser realizada enquanto este comando estiver em processamento). O >VACUUM simples apenas remove as tuplas marcadas como inúteis/removidas em processos de >UPDATE ou >DELETE. Sendo assim, não há necessidade de bloquear as operações no banco. Por outro lado, o >VACUUM FULL além de remover essas tuplas inúteis, ainda reorganiza as tabelas, retirando os espaços em branco que ficaram após a remoção dessas colunas, e para tal processo é necessário que o banco não esteja realizando nenhuma operação, por isso o bloqueio do mesmo é necessário.
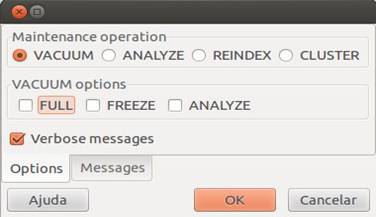
Caso você utilize o >pgAdmin como uma ferramenta para realizar o gerenciamento do seu PostgreSQL, então nele mesmo (sem linha de comando) você poderá realizar o >VACUUM, assim como outros processos otimizadores de performance.
O processo é simples: basta você clicar com o botão direito em cima da sua base de dados e depois escolher a opção “>Maintenance...”, então você verá uma janela como mostrada na Figura 2.
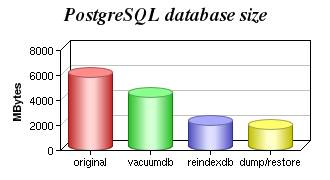
O Vacuum diminui consideravelmente o tamanho físico do banco, mas não só isso, ele também aumenta a performance do otimizador do banco de dados. Além dele, ainda existem outras ferramentas, como falamos em seções anteriores. No gráfico da Figura 3 você pode visualizar de forma mais abrangente a diferença física de espaço em seu banco após realizar processos de otimização do banco, tais como: >vacuum, >reindex e outros.
O próprio PostgreSQL já possui um processo chamado >autovacuum onde você pode deixar que o próprio banco realize o >Vacuum Simples (sem o FULL) com frequência, o que é muito bom para base de dados, pois as deleções e atualizações de registros são constantes e você mantêm sua base sempre rápida e sem dados sujos. Por outro lado, a própria documentação original do PostgreSQL aconselha que o >VACUUM FULL seja usado como muito cuidado e em casos raros, isso porque o processo demanda muito tempo e pode até causar baixa de performance no banco, em vez de melhor a mesma, isso porque o processo faz algo muito crítico, que é a reorganização de todas as tuplas, retirando os '>gaps' que ficaram após a remoção dos registros inúteis.
Com isso, este artigo teve como principal objetivo demonstrar técnicas mais avançadas do PostgreSQL para análise de performance e otimização do banco, assunto este essencial e obrigatório para >DBA's. Vale ressaltar que todas as técnicas descritas neste artigo devem ser usadas com cautela e sempre mediante a uma análise prévia do problema, em outras palavras, não saia executando >VACUUM em todas as suas tabelas e bancos antes de analisar a real necessidade de aplicar este procedimento. Como citamos anteriormente, a própria documentação do PostgreSQL aconselha o não uso do >VACUUM FULL, que pode ser prejudicial ao banco de dados, se aplicado de forma errônea, obviamente.
Quando vacuum estiver sem parâmetro, ele irá processar cada tabela do banco de dados, mas quando existe algum parâmetro no vacuum somente a tabela é processada.
VACUUM ANALYZE
Executa um vacuum e depois um analyze para cada tabela selecionada. Esta é uma forma de combinação para manutenção rotineira de scripts, veja ANALYZE para mais informações a respeito do processamento.
Somente vacuum, simplesmente reivindica espaço e o torna disponível para a reutilização.
Utilizando o Vacuum Analyze:
$ VACUUM ANALYZE tabela;
Se você quiser ver o status, utilize o parâmetro VERBOSE:
$ VACUUM ANALYZE VERBOSE tabela;
VACUUM FULL
Realiza um processamento mais extensivo, inclusive movendo as tuplas através de blocos, para tentar compactar a tabela ao número mínimo de blocos. Esta forma é muito lenta e exige um bloqueio exclusivo em cada tabela enquanto estiver sendo processada:
$ VACUUM FULL;
Se você quiser ver o status, utilize o paramento VERBOSE:
$ VACUUM FULL VERBOSE;
https://www.postgresql.org/docs/11/sql-vacuum.html
- Renato de O. Lucena - 30/10/2019
Donate to Site

Renato
Developer