Posted on: September 29, 2022 01:12 AM
Posted by: Renato
Categories: Laravel PHP arquitetura Architecture Dicas
Views: 3238
# Clean Architecture
Arquitetura de software é sempre um tema interessante, pois conhecendo as vantagens e desafios das principais arquiteturas é possível aumentar consideravelmente a qualidade e escalabilidade de um software. Por isso, neste artigo vamos falar sobre a Clean Architecture, ou Arquitetura Limpa em português.

Por que estudar arquitetura de software?
Nos últimos anos o tópico arquitetura de software tem despertado bastante interesse, indiferente da senioridade das pessoas. O que faz total sentido, se analisarmos que a cada dia fica mais evidente que, independente do tamanho da equipe (seja ela de um único membro atuante na construção de uma startup, ou múltiplas equipes trabalhando em paralelo nos grandes projetos) devemos sempre considerar a arquitetura de software a ser adotada, visando evitar um possível colapso no futuro, tornando o software a ser construído mais robusto, flexível e escalável.
Sem contar que um software que não seja tolerável a mudanças, dificulta consideravelmente a implementação de novos requisitos necessários para a sua evolução, assim como a sua manutenção.
Com a nossa arquitetura bem definida temos a organização do nosso código, a definição de como eles se relacionam entre si, assim como interagem com elementos externos, tais como o banco de dados ou interface do usuário.
Dentro de um leque de diferentes opções de arquitetura de software, há algumas que se destacam consideravelmente, a Clean Architecture.
# Mas o que é o Clean Architecture?
Clean Architecture é uma arquitetura de software proposta por Robert Cecil Martin (ou Uncle Bob, como é mais conhecido) que tem por objetivo padronizar e organizar o código desenvolvido, favorecer a sua reusabilidade, assim como independência de tecnologia.
A Clean Architecture foi criada por Robert C. Martin e promovida em seu livro Clean Architecture: A Craftsman’s Guide to Software Structure. Assim como outras filosofias de design de software, a Clean Architecture tenta fornecer uma metodologia a ser usada na codificação, a fim de facilitar o desenvolvimento códigos, permitir uma melhor manutenção, atualização e menos dependências.
Por mais que a Clean Architecture foi criada em meados de 2012, está repleta de princípios atemporais que podem ser aplicados independente da tecnologia utilizada e linguagem de programação.
Entenda a infraestrutura por trás da Arquitetura Limpa
Na imagem abaixo, temos a representação de uma arquitetura em camadas (Layered Architecture) tradicional, onde as setas esboçam a direção das dependências seguindo um fluxo do topo para baixo.
Assim, a interface do usuário depende da camada de domínio, que por sua vez depende da camada de acesso ao banco de dados.
Com isso podemos observar que existe um acoplamento forte entre as camadas, de forma que, para substituir a camada de banco de dados precisamos alterar a camada de domínio.
"User Interface -> Domain -> Data Access library"
Robert “Uncle Bob” Martin, se refere fortemente à organização do projeto visando o fácil entendimento e que seja ágil a mudanças, conforme as necessidades encontradas no amadurecimento do software. Para assim termos a capacidade de desenvolver encapsulando toda a lógica de negócios, de forma intrinsecamente testável, independentemente do restante da infraestrutura.
Conforme Mark Seeman, as abstrações não devem depender de detalhes, e sim os detalhes devem depender de abstrações. Com isso, nesta segunda imagem, o fluxo de dependência entre as camadas, centraliza a camada de domínio, com uma simples alteração na direção da seta que liga a camada de domínio com a de acesso ao banco de dados.
"User Interface -> Domain -> Data Access library"
Como podemos ver, uma vantagem da Clean Architecture em comparação com as arquiteturas tradicionais de três camadas, se dá pelo fato de poder definir estes componentes de infraestrutura em um momento posterior, assim como removê-los ou substituí-los com uma complexidade reduzida.
Em outras palavras, podemos projetar aplicativos com menor acoplamento e independentes de detalhes técnicos de implementação, como bancos de dados e estruturas.
## Clean Architecture: muito mais do que camadas
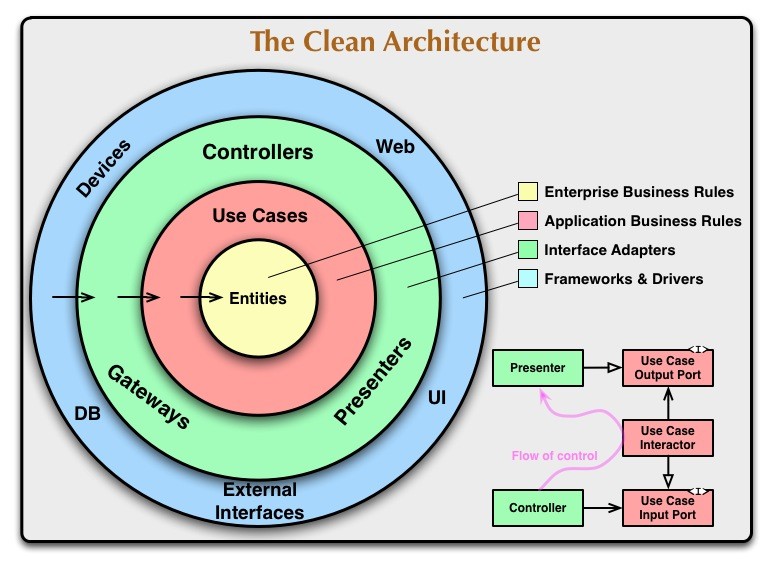
Dentre as principais regras do Clean Architecture, devemos ter maior atenção ao fato que podemos mover as dependências apenas dos níveis externos para os internos, conforme as setas apresentadas na clássica imagem abaixo.
Com isso, os códigos nas camadas internas não precisam ter conhecimento necessariamente das funções nas camadas externas. Os níveis mais internos não podem mencionar as variáveis, funções e classes que existem nas camadas externas.
# Mas afinal por que separar em camadas?
Partindo do princípio de que esta regra de dependência está sendo bem aplicada, esta separação de camadas visa nos poupar de problemas futuros com a manutenção do software. Deixando, inclusive, o sistema completamente testável, pois as regras de negócios podem ser validadas sem a necessidade da interface do usuário, banco de dados, servidor ou qualquer outro elemento externo.
Outro ponto de extrema relevância, por ser uma arquitetura de software amplamente independente, é que a princípio conseguimos fazer a substituição da interface do usuário sem que isso reflita no resto do sistema.
Assim como podemos trocar o banco de dados, por exemplo, de Oracle ou SQL Server, por Mongo, DynamoDB ou qualquer outro, pois suas regras de negócios não estão vinculadas ao banco de dados, nos facilitando a troca destes componentes caso tenham se tornado obsoletos ou por qualquer outra necessidade de negócio/técnica sem encontrar maiores dificuldades.
Clean Architecture é um assunto bastante amplo. Por isso, espero ter te instigado a estudar mais sobre o tema e sobre arquitetura de software como um todo.
Fica claro que as ideias propostas por Uncle Bob, tendem a organizar o nosso código, padronizando o desenvolvimento do software, visando facilitar inclusive o trabalho em equipe.
------------------------------------------------------------------------------------------------------------------
"Objetivo: O objetivo é mostrar que podemos adequar qualquer design de software mantendo seus princípios para chegar em uma solução que possa ser adequada para cada tipo de problema.
Inspiração: Esse artigo é inspirado em situações e dificuldades reais já vivenciadas que me fez ter uma visão um pouco mais abrangente sobre ter um ideal de arquitetura."
# Como implementar Arquitetura Limpa com Laravel
E isso é compreensível: a arquitetura MVC do Laravel e sua tendência de permitir que você cruze camadas o tempo todo usando Facades não ajuda a projetar partes de software limpas e desacopladas.
Então, hoje, vou apresentar a você uma implementação funcional dos princípios da Arquitetura Limpa dentro de um aplicativo Laravel , conforme explicado em A Arquitetura Limpa de Robert C. Martin .
A implementação completa e funcional dos conceitos explicados aqui está disponível no meu repositório GitHub . Eu recomendo que você dê uma olhada no código real enquanto lê este artigo.
Por uma vez, vamos limpar as mãos 👍
Tudo começou com um diagrama
( A Arquitetura Limpa capítulo 16, pág. 148.)
Se você nunca ouviu falar de casos de uso, pode pensar nisso como um recurso , a capacidade de um sistema de fazer algo significativo. A UML permite descrevê-los usando os bem nomeados Diagramas de Caso de Uso .
Na CA , os casos de uso estão no centro do aplicativo. Eles são o microchip que controla o maquinário do seu aplicativo.
Então, como devemos implementar esses casos de uso então?
Que bom que você perguntou! Aqui está um segundo diagrama:
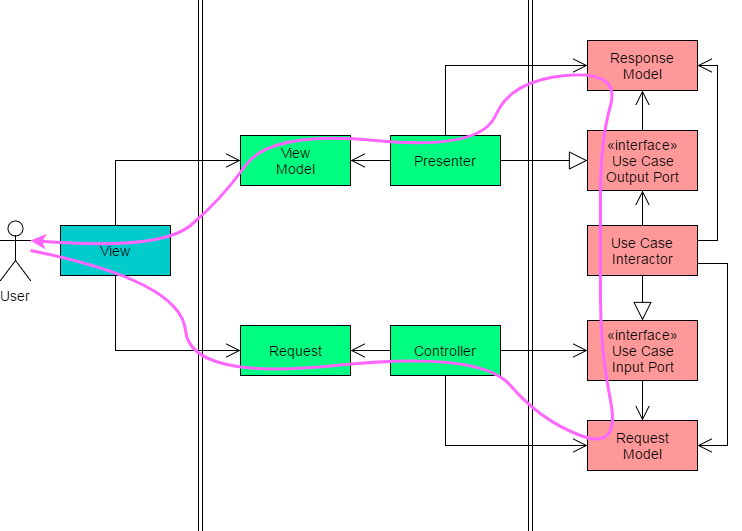
Deixe-me explicar brevemente, e vamos mergulhar no código real .
A linha rosa é o fluxo de controle ; ele representa a ordem em que os diferentes componentes estão sendo executados. Primeiro, o usuário altera algo na visualização (por exemplo, ele envia um formulário de registro). Essa interação torna-se um Requestobjeto. O controlador o lê e produz um RequestModela ser usado pelo UseCaseInteractor.
O UseCaseInteractorentão faz o seu trabalho (por exemplo, cria o novo usuário), prepara uma resposta na forma de um ResponseModele passa para o Presenter. O que, por sua vez, atualiza a exibição por meio de um arquivo ViewModel.
Uau, isso é muito 😵 Essa é provavelmente a principal crítica feita ao CA ; é comprido !
A hierarquia de chamadas se parece com isso:
Controller(Request)
⤷ Interactor(RequestModel)
⤷ Presenter(ResponseModel)
⤷ ViewModel
E os portos?
Eu posso ver que você é bastante observador! Para que as camadas de baixo nível (os Casos de Uso e as Entidades, muitas vezes chamadas de Domínio e representadas como os círculos vermelho e amarelo no esquema acima) sejam desacopladas das camadas de alto nível (a estrutura, representada como o azul círculo), precisamos de adaptadores (o círculo verde). Seu trabalho é transmitir mensagens entre camadas altas e baixas usando suas respectivas APIs e contratos (ou interfaces).
Os adaptadores são absolutamente cruciais na CA. Eles garantem que mudanças no framework não exigirão mudanças no domínio e vice-versa. No CA , queremos que nossos casos de uso sejam abstraídos do framework (a implementação real) para que ambos possam mudar à vontade sem propagar as alterações em outras camadas.
Um aplicativo PHP/HTML tradicional projetado com arquitetura limpa pode, portanto, ser transformado em uma API REST apenas alterando seus controladores e apresentadores - os Casos de Uso permaneceriam intocados! Ou você pode ter HTML + REST lado a lado usando os mesmos Casos de Uso. Isso é muito legal se você me perguntar 🤩
Para fazer isso, precisamos "forçar" o adaptador a "se comportar" da maneira que cada camada precisa que ele se comporte. Vamos usar interfaces para definir portas de entrada e saída . Eles dizem, em essência, "se você quer falar comigo, você vai ter que fazer assim!"
Blá blá blá. Eu quero ver algum código!
Já que o UseCaseInteractorestará no centro de tudo, vamos começar com este:
class CreateUserInteractor implements CreateUserInputPort
{
public function __construct(
private CreateUserOutputPort $output,
private UserRepository $repository,
private UserFactory $factory,
) {
}
public function createUser(CreateUserRequestModel $request): ViewModel
{
/* @var UserEntity */
$user = $this->factory->make([
'name' => $request->getName(),
'email' => $request->getEmail(),
]);
if ($this->repository->exists($user)) {
return $this->output->userAlreadyExists(
new CreateUserResponseModel($user)
);
}
try {
$user = $this->repository->create(
$user, new PasswordValueObject($request->getPassword())
);
} catch (\Exception $e) {
return $this->output->unableToCreateUser(
new CreateUserResponseModel($user), $e
);
}
return $this->output->userCreated(
new CreateUserResponseModel($user)
);
}
}
Há 3 coisas que precisamos prestar atenção aqui:
O interator implementa a CreateUserInputPortinterface,
O interator depende do CreateUserOutputPort,
O interator não faz a ViewModelsi mesmo, mas diz ao apresentador para fazê-lo,
Como o Presenter(abstraído aqui por CreateUserOutputPort) está localizado na camada de adaptadores (verde), chamá-lo de the CreateUserInteractoré de fato um excelente exemplo de inversão de controle : o framework não está controlando os casos de uso, os casos de uso estão controlando o framework.
Se você achar muito complicado, esqueça tudo isso e considere que todas as decisões significativas estão sendo tomadas no nível do caso de uso - incluindo a escolha do caminho de resposta ( userCreated, userAlreadyExists, ou unableToCreateUSer). O controlador e os apresentadores são apenas escravos obedientes, desprovidos de lógica de negócios.
Nunca podemos ensaiar o suficiente, então cante comigo: CONTROLADORES 👏 DEVEM 👏 NÃO 👏 CONTER 👏 NEGÓCIOS 👏 LÓGICA 👏
Então, como é a perspectiva do controlador?
Para o controlador, a vida é simples:
class CreateUserController extends Controller
{
public function __construct(
private CreateUserInputPort $interactor,
) {
}
public function __invoke(CreateUserRequest $request)
{
$viewModel = $this->interactor->createUser(
new CreateUserRequestModel($request->validated())
);
return $viewModel->getResponse();
}
}
Você pode ver que depende da CreateUserInputPortabstração em vez da CreateUserInteractorimplementação real. Isso nos dá a flexibilidade de alterar o caso de uso à vontade e tornar o controlador testável. Mais sobre isso mais tarde.
Ok, isso é muito simples e estúpido de fato. E o apresentador?
Mais uma vez, muito simples:
class CreateUserHttpPresenter implements CreateUserOutputPort
{
public function userCreated(CreateUserResponseModel $model): ViewModel
{
return new HttpResponseViewModel(
app('view')
->make('user.show')
->with(['user' => $model->getUser()])
);
}
public function userAlreadyExists(CreateUserResponseModel $model): ViewModel
{
return new HttpResponseViewModel(
app('redirect')
->route('user.create')
->withErrors(['create-user' => "User {$model->getUser()->getEmail()} alreay exists."])
);
}
public function unableToCreateUser(CreateUserResponseModel $model, \Throwable $e): ViewModel
{
if (config('app.debug')) {
// rethrow and let Laravel display the error
throw $e;
}
return new HttpResponseViewModel(
app('redirect')
->route('user.create')
->withErrors(['create-user' => "Error occured while creating user {$model->getUser()->getName()}"])
);
}
}
Tradicionalmente, todo esse código estaria ifsno final do controlador. O que teria forçado o caso de uso a encontrar uma maneira de "dizer" ao controlador o que aconteceu (usando $user->wasRecentlyCreatedou lançando exceções, por exemplo).
O uso de apresentadores controlados pelo caso de uso nos permite escolher e alterar os resultados sem tocar no controlador. Quão grande é isso?
Então tudo depende de abstrações, imagino que o container vai se envolver em algum momento?
Tens toda a razão, meu bom amigo! Agrada-me estar em boa companhia hoje.
Veja como conectar tudo isso em app/Providers/AppServiceProvider.php:
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
// wire the CreateUser use case to HTTP
$this->app
->when(CreateUserController::class)
->needs(CreateUserInputPort::class)
->give(function ($app) {
return $app->make(CreateUserInteractor::class, [
'output' => $app->make(CreateUserHttpPresenter::class),
]);
});
// wire the CreateUser use case to CLI
$this->app
->when(CreateUserCommand::class)
->needs(CreateUserInputPort::class)
->give(function ($app) {
return $app->make(CreateUserInteractor::class, [
'output' => $app->make(CreateUserCliPresenter::class),
]);
});
}
}
Adicionei a variante CLI para demonstrar como é fácil trocar o apresentador para que o caso de uso retorne ViewModelinstâncias diferentes. Dê uma olhada na implementação real para mais detalhes 👍
Posso testar isso?
Oh meu Deus! Está implorando para você! Outra coisa boa sobre a CA é que ela depende tanto de abstrações que facilita muito os testes.
class CreateUserUseCaseTest extends TestCase
{
use ProvidesUsers;
/**
* @dataProvider userDataProvider
*/
public function testInteractor(array $data)
{
(new CreateUserInteractor(
$this->mockCreateUserPresenter($responseModel),
$this->mockUserRepository(exists: false),
$this->mockUserFactory($this->mockUserEntity($data)),
))->createUser(
$this->mockRequestModel($data)
);
$this->assertUserMatches($data, $responseModel->getUser());
}
}
A classe de teste completa está disponível aqui . https://github.com/bdelespierre/laravel-clean-architecture-demo/blob/master/tests/Unit/CreateUserUseCaseTest.php
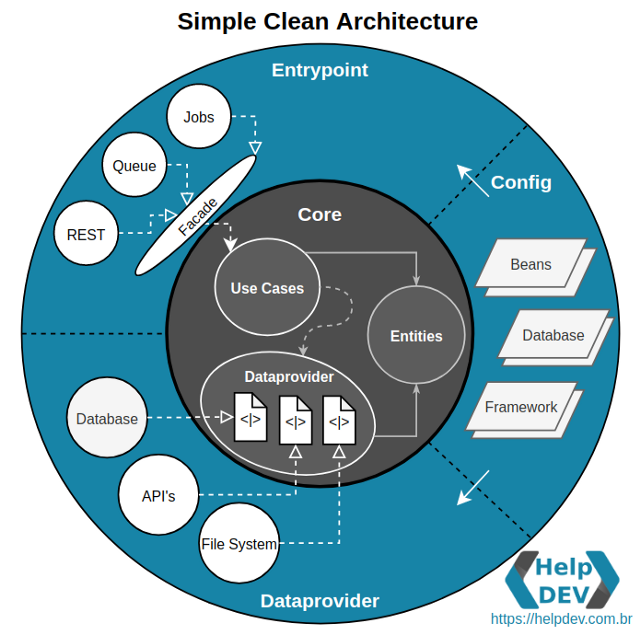
Fontes:
https://dev.to/bdelespierre/how-to-implement-clean-architecture-with-laravel-2f2i
https://www.zup.com.br/blog/clean-architecture-arquitetura-limpa
https://medium.com/luizalabs/descomplicando-a-clean-architecture-cf4dfc4a1ac6
https://niceprogrammer.com/laravel-8-clean-architecture-example/?unapproved=2975&moderation-hash=90b5222c9af1c411e7e7efd4e6061ba0#comment-2975
Modelos de codigo:
https://github.com/cpdrenato/clean-architecture-sample
https://github.com/cpdrenato/laravel-clean-architecture-demo
https://github.com/cpdrenato/symfony-clean-architecture-demo
Leitura adicional:
Donate to Site

Renato
Developer